Turbo編碼器提升毫微微蜂窩DSP的效率
最近,小型毫微微蜂窩基站概念在移動(dòng)應(yīng)用中越來越受歡迎。與傳統(tǒng)宏蜂窩相比,毫微微蜂窩在覆蓋范圍、兼容性和成本方面都具有優(yōu)勢(shì)。
由于成本和性能的制約,毫微微蜂窩設(shè)計(jì)必須具有與宏蜂窩大致相同的模塊化水平和復(fù)雜度,并且與個(gè)人而非社群的經(jīng)濟(jì)承受能力相適應(yīng)。
但是,為了實(shí)現(xiàn)至少與傳統(tǒng)宏蜂窩系統(tǒng)相同的信號(hào)強(qiáng)度,毫微微蜂窩必須采用支持高達(dá)14.4 Mbps比特率的多通道設(shè)計(jì)。因此,設(shè)計(jì)人員面臨著嚴(yán)峻挑戰(zhàn):利用系統(tǒng)的數(shù)字信號(hào)處理(DSP)引擎編碼多通道比特流,同時(shí)為系統(tǒng)的其它關(guān)鍵操作提供足夠的計(jì)算裕量。
本文介紹如何實(shí)現(xiàn)基于Turbo編碼的高效算法以支持基于Blackfin的14.4 Mbps 3G毫微微蜂窩設(shè)計(jì),該設(shè)計(jì)僅消耗Blackfin可提供的600 MIPS計(jì)算能力中的100 MIPS,從而為系統(tǒng)的其它必要操作留下了充沛的資源。
Turbo碼性能卓越,因此自1993年推出以來,便在業(yè)界和學(xué)術(shù)界引起了極大的關(guān)注。Turbo碼的工作效率幾乎達(dá)到了香農(nóng)所確定的信道容量極限,信噪比(SNR)間隔小于或等于0.7dB。
Turbo碼最初由Berrou、Glavieux和Thitimajshima提出1,它是利用兩個(gè)并行級(jí)聯(lián)的卷積編碼器構(gòu)建而成。在Turbo編碼方案中,同一信息序列的不同交織版本上產(chǎn)生兩個(gè)分量碼。在解碼器端,使用兩個(gè)最大后驗(yàn)概率(MAP)解碼器以迭代方式解碼判決結(jié)果。MAP解碼算法使用接收到的數(shù)據(jù)和奇偶校驗(yàn)符號(hào)(對(duì)應(yīng)于根據(jù)真實(shí)和交織形式的數(shù)據(jù)位計(jì)算而來的奇偶校驗(yàn)位)及其它解碼器軟輸出(外部)的信息,產(chǎn)生更可靠的判決結(jié)果。
關(guān)于Turbo碼的高效解碼,學(xué)術(shù)界已提出了許多算法和實(shí)現(xiàn)技術(shù),但有關(guān)如何高效實(shí)現(xiàn)Turbo編碼器以支持高比特率應(yīng)用的技術(shù)則不多見。在基站等應(yīng)用中,一次須傳輸多個(gè)數(shù)據(jù)流。因此,必須高效實(shí)現(xiàn)Turbo編碼器,使之能以較少的處理能力編碼多個(gè)比特流。
毫微微蜂窩的服務(wù)對(duì)象是個(gè)體而非群體,因此用戶將擁有專屬的無線基礎(chǔ)設(shè)施,能夠?yàn)槠渌幸苿?dòng)設(shè)備提供良好的信號(hào)強(qiáng)度。就數(shù)據(jù)處理而言,宏蜂窩與毫微微蜂窩的模塊和復(fù)雜度大致相同。但是,毫微微蜂窩設(shè)計(jì)的目標(biāo)用戶是個(gè)人而非群體,所以應(yīng)做到價(jià)格低廉。因此,在毫微微蜂窩設(shè)計(jì)中使用多個(gè)昂貴的處理器件并不現(xiàn)實(shí)。本文并未闡述毫微微蜂窩完整架構(gòu)的細(xì)節(jié),但在討論用于無線網(wǎng)絡(luò)糾錯(cuò)功能的3G標(biāo)準(zhǔn)2 Turbo編碼時(shí),已特別注意了毫微微蜂窩設(shè)計(jì)的預(yù)算要求。
3G Turbo編碼器的實(shí)現(xiàn)
Turbo編碼器主要包括兩個(gè)成分編碼器,一個(gè)交織器將二者隔開。3G Turbo遞歸系統(tǒng)碼(RSC)編碼器的原理框圖如圖1所示。每個(gè)RSC編碼器均包括一個(gè)傳遞函數(shù)為(1+D+D3)的正向通道和一個(gè)傳遞函數(shù)為(1+D2+D3)的反饋通道。每個(gè)輸入的交織地址產(chǎn)生過程參見3GPP的論文2。利用雙MAC(乘法累加器)DSP(如Blackfin等)無法即時(shí)計(jì)算交織地址,除非我們有許多計(jì)算單元。
3G Turbo遞歸系統(tǒng)碼[RSC]編碼器
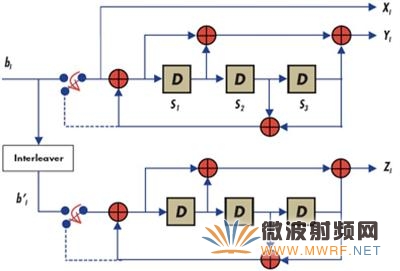
圖1.
通常是預(yù)先計(jì)算交織地址,并將其存儲(chǔ)在存儲(chǔ)器中。存儲(chǔ)的交織地址可以用于Turbo編碼和解碼。如果碼字很大,則預(yù)計(jì)算的交織地址存儲(chǔ)在L3存儲(chǔ)器中,否則存儲(chǔ)在L1存儲(chǔ)器中。對(duì)于更大的碼字,我們使用窗口方法編碼或解碼各位,并使用直接存儲(chǔ)器訪問方法根據(jù)需要從L3傳輸數(shù)據(jù)(如輸入和交織地址等)。
由圖1可知,對(duì)于每個(gè)輸入,我們輸出一個(gè)系統(tǒng)位Xi和兩個(gè)奇偶校驗(yàn)位Yi和Zi。這里,奇偶校驗(yàn)位Zi并不直接取決于實(shí)際輸入位bi,而是取決于交織緩沖器中索引為i的位b'i。給定N位的輸入消息塊B時(shí),我們或者執(zhí)行地址計(jì)算,從塊B獲得各輸入位索引的交織位b'i,或者立即執(zhí)行整個(gè)塊B的交織,并存儲(chǔ)為交織塊B',然后用索引i線性訪問b'i。請(qǐng)注意,根據(jù)3G標(biāo)準(zhǔn)計(jì)算交織位地址并非易事,因此,我們傾向于在開始編碼多個(gè)消息數(shù)據(jù)塊之前,預(yù)先計(jì)算所有N位的地址,并將其一次性存儲(chǔ)在存儲(chǔ)器中。這樣,我們就能忽略Turbo編碼產(chǎn)生交織地址的復(fù)雜性。
簡(jiǎn)單編碼。在簡(jiǎn)單編碼中,我們逐位編碼。對(duì)于每個(gè)輸入位,我們輸出三位。模擬RSC編碼器的一段C代碼樣例如表1所示。通常,輸入數(shù)據(jù)位以8位字節(jié)的形式從存儲(chǔ)器存取,因?yàn)樘幚砥骺梢詮拇鎯?chǔ)器存取的最小數(shù)據(jù)為一個(gè)字節(jié)(或一個(gè)8位量)。獲得一個(gè)字節(jié)的數(shù)據(jù)后,為了逐位進(jìn)行編碼,必須拆包各位,每位需要大約1.125周期(總共9個(gè)周期:使用Blackfin rot指令,第一位拆包需要2個(gè)周期,其余各位需要1個(gè)周期)。然后,編碼此位又需要7個(gè)周期,因?yàn)榫幋a僅涉及到序列化操作。完成編碼后,必須將編碼位封包,并存儲(chǔ)在存儲(chǔ)器中,以便進(jìn)行其它處理和傳輸。數(shù)據(jù)封包所需的周期數(shù)與拆包相同,即每位1.125周期。因此,編碼1位數(shù)據(jù)并輸出1個(gè)奇偶校驗(yàn)位總共需要10個(gè)周期(包括開銷)。

計(jì)算復(fù)雜度。由于我們使用查找表來檢索交織地址,而不是即時(shí)計(jì)算,因此只有訪問查找表需要一些周期(可能不涉及計(jì)算操作)。交織一個(gè)數(shù)據(jù)位需要大約三個(gè)周期(一個(gè)周期用于加載偏移,兩個(gè)周期用于計(jì)算絕對(duì)地址)。Turbo編碼涉及到兩個(gè)RSC編碼器和一個(gè)交織操作,因此編碼一個(gè)數(shù)據(jù)位總共需要25個(gè)周期(包括開銷)。對(duì)于14.4 Mbps比特率的毫微微蜂窩應(yīng)用,我們需要大約360 MIPS,即約60%的Blackfin處理器MIPS。
Turbo碼的處理
如前所述,如果實(shí)現(xiàn)不當(dāng),更高比特率的Turbo編碼器將是一個(gè)昂貴的模塊。接下來,我們將討論高效實(shí)現(xiàn)Turbo編碼器的技術(shù)。我們將Turbo編碼器分為兩部分:第一部分是來處理位的編碼,第二部分是處理數(shù)據(jù)位的交織。
使用查找表進(jìn)行編碼。如前所述,使用兩個(gè)RSC編碼器進(jìn)行Turbo編碼時(shí),每個(gè)輸入位需要大約20個(gè)周期。下面我們將介紹一種不同的使用查找表方法,每個(gè)輸入位只需2.5個(gè)周期(用于兩個(gè)編碼器)。為了存儲(chǔ)查找表數(shù)據(jù),需要256個(gè)字節(jié)的額外存儲(chǔ)器。考慮到RSC編碼器的目前狀態(tài),使用查找表一次可以編碼多個(gè)位。通過預(yù)先計(jì)算長(zhǎng)度L的輸入位的所有可能組合和狀態(tài)位的所有三種組合的查找表,我們一次可以編碼L位。在這種編碼中,我們使用的查找表含有2L+3項(xiàng)。隨著L值增大,查找表也會(huì)增大。L = 4時(shí)(換言之,一次編碼4位),查找表含有27或128項(xiàng),如圖2所示。各項(xiàng)包含4個(gè)編碼位和3位更新狀態(tài)信息。換言之,一個(gè)字節(jié)(或8位)足以代表查找表的各項(xiàng)。
基于查找表的Turbo編碼
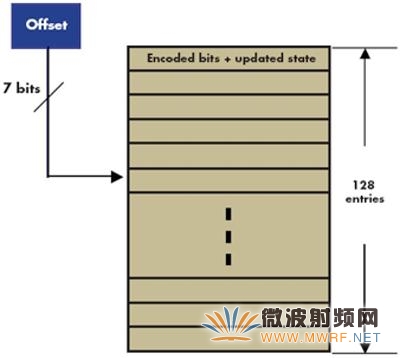
圖2.
深入研究8位查找表設(shè)計(jì)可以發(fā)現(xiàn),為了從4個(gè)輸入位(假設(shè)位于寄存器r0)和3個(gè)當(dāng)前狀態(tài)位(假設(shè)位于寄存器r1)計(jì)算128項(xiàng)查找表的7位偏移,我們必須從輸入字節(jié)(或從r0)提取(1個(gè)周期)4個(gè)數(shù)據(jù)位(假設(shè)存入寄存器r2),從前一編碼的查找表輸出(或從r1)提取(1個(gè)周期)當(dāng)前狀態(tài)(假設(shè)存入寄存器r3),將3個(gè)狀態(tài)位移動(dòng)(1個(gè)周期)4位(r3 = r3<<4),以及對(duì)提取的4個(gè)輸入數(shù)據(jù)位至狀態(tài)位求“或”(1個(gè)周期;即r4 = r2|r3)。只要正確設(shè)計(jì)查找表,我們就能避免狀態(tài)位的提取和移位操作。如果我們對(duì)各查找表項(xiàng)使用兩個(gè)字節(jié),并將狀態(tài)位置于移位位置,如圖3所示,我們就能省掉兩個(gè)偏移計(jì)算周期(節(jié)約50%)。
高效Turbo編碼的查找表設(shè)計(jì)

圖3.
完成編碼位的計(jì)算之后,我們必須將編碼位封包。我們一次編碼4位,并且一次輸出一個(gè)編碼的4位半字節(jié),因此將半字節(jié)封包成字節(jié)是很容易的事。我們用兩個(gè)周期將兩個(gè)半字節(jié)封包成一個(gè)字節(jié),一個(gè)周期用于左移,另一個(gè)周期用于“或”或“和”運(yùn)算。對(duì)于雙編碼器輸出封包,Blackfin需要四個(gè)周期。利用乘法累加器(MAC),我們可以在兩個(gè)周期內(nèi)完成兩個(gè)編碼器的封包工作,因?yàn)锽lackfin有兩個(gè)MAC單元。對(duì)于單迭代循環(huán),用于Turbo編碼器編碼和封包的Blackfin ASM代碼如表2所示。該ASM代碼包括兩個(gè)RSC編碼器的編碼和封包。ASM代碼清楚地顯示,一個(gè)字節(jié)的Turbo編碼需要20個(gè)周期,或者說每個(gè)位需要2.5個(gè)周期。


在表2中,借助此ASM代碼,我們可一次實(shí)現(xiàn)兩個(gè)編碼器的4位數(shù)據(jù)編碼。但實(shí)際上,第二個(gè)編碼器并不直接從輸入比特流字節(jié)中獲得數(shù)據(jù)。傳送給第二編碼器之前,我們必須對(duì)輸入比特流進(jìn)行交織處理。我們已經(jīng)討論了第二個(gè)編碼器的交織,交織位存儲(chǔ)在交織緩沖器中。我們假設(shè),通過將交織位存儲(chǔ)在可尋址的邊界內(nèi)(換言之,存儲(chǔ)一位必須使用最小的字節(jié)),所存儲(chǔ)的交織位可以直接從緩沖器存取進(jìn)行編碼。由于我們是利用查找表方法以半字節(jié)形式進(jìn)行編碼,因此必須先將交織位封包成字節(jié),再將其存儲(chǔ)在交織緩沖器中。
交織器設(shè)計(jì)。由于上述基于查找表的編碼方法需要字節(jié)形式的交織位,因此必須將交織位封包成字節(jié)。這樣,為了以正確的順序?qū)⑦@些位送入第二個(gè)編碼器,必須執(zhí)行以下三個(gè)步驟:拆包、交織、封包。我們以字節(jié)表示數(shù)據(jù),封包是將位多路復(fù)用為字節(jié),拆包是將字節(jié)解多路復(fù)用為位。將位封包成字節(jié)需要所有交織位,我們首先必須完成交織處理。對(duì)于這兩種操作(拆包和交織),每位大約需要3個(gè)周期,如表3所示。表3中的ASM代碼對(duì)一個(gè)字節(jié)的輸入數(shù)據(jù)執(zhí)行拆包和交織處理。帶進(jìn)位的循環(huán)移位指令rot r by -1可提供從結(jié)尾最高有效位(MSB)開始的拆包數(shù)據(jù)位。

下一步是將交織數(shù)據(jù)位封包成字節(jié)。封包操作與表3所示的拆包操作完全相反。但是,如果我們使用進(jìn)位循環(huán)指令rot r by 1進(jìn)行封包,則每位需要2個(gè)周期,其中一個(gè)周期用于將寄存器中的數(shù)據(jù)位移入cc。因此,我們不使用循環(huán),而使用比較和選擇指令vit_max進(jìn)行封包。vit_max指令將兩個(gè)寄存器中存在的兩個(gè)最低有效位(LSB)字與同一寄存器的兩個(gè)MSB字相比較,從而一次封包兩位。vit_max指令的比較結(jié)果輸出標(biāo)志保存于累加器中,經(jīng)過四次迭代后,我們從累加器中提取封包的字節(jié)。由于我們無法在一個(gè)周期內(nèi)從同一緩沖器加載兩位數(shù)據(jù)提供給vit_max指令,因此必須再花一個(gè)周期來加載數(shù)據(jù)位。這樣,封包兩位需要兩個(gè)周期,或者一位一個(gè)周期,如表4所示。

計(jì)算復(fù)雜度評(píng)估
無論是依據(jù)每位周期數(shù)來評(píng)估,還是依據(jù)執(zhí)行任務(wù)所需的存儲(chǔ)空間來評(píng)估,這種Turbo碼算法實(shí)現(xiàn)方法的計(jì)算負(fù)荷都是相對(duì)適中的。
周期估算。如表3和表4所示,對(duì)交織數(shù)據(jù)執(zhí)行拆包、交織和封包處理,每位需要4個(gè)周期。在表2所示的數(shù)據(jù)編碼中,每位需要2.5個(gè)周期。這樣,Turbo編碼器總的周期成本為每位6.5個(gè)周期。請(qǐng)注意,這一估算沒有考慮周期開銷。假設(shè)每位的開銷為1個(gè)周期,則執(zhí)行Turbo編碼,每位需要大約7.5個(gè)周期。借助這一高效的實(shí)現(xiàn)方法,我們?cè)?4.4 Mbps比特率時(shí)只需使用Blackfin處理器的108 MIPS,或者約18%的處理器MIPS。相比之下,簡(jiǎn)單編碼方法則需要使用60%的處理器MIPS。由于Turbo編碼器只消耗18%的MIPS,還剩下約82%的處理器MIPS,因此我們有充足的裕量來應(yīng)對(duì)毫微微蜂窩基站的其它模塊。
存儲(chǔ)空間估算。利用查找表方法實(shí)現(xiàn)Turbo編碼時(shí),我們需要256字節(jié)的數(shù)據(jù)存儲(chǔ)空間來存儲(chǔ)預(yù)計(jì)算的編碼信息。采用高效方法時(shí),我們將各位封包成字節(jié),因而存儲(chǔ)交織數(shù)據(jù)所需的數(shù)據(jù)存儲(chǔ)空間更小(僅1/8)。即時(shí)計(jì)算交織地址的方法非常昂貴,所以兩種方法均需要數(shù)據(jù)存儲(chǔ)器來存儲(chǔ)交織地址。
利用預(yù)先計(jì)算的查找表,我們可以僅使用18%的處理器MIPS來執(zhí)行Turbo編碼;否則,使用簡(jiǎn)單方法則要消耗約60%的MIPS。這種高效方法使用256字節(jié)的存儲(chǔ)器來存儲(chǔ)查找表,所用的總存儲(chǔ)空間少于簡(jiǎn)單方法所需的存儲(chǔ)空間。
作者:Hazarathaiah Malepati和Yosi Stein,ADI半導(dǎo)體
參考文獻(xiàn)
1. Berrou C, A Glavieux, and P. Thitimajshima,, "Near Shannon Limit Error-Correcting Coding: Turbo Codes," Proc IEEE Int. Conf. Commun., Geneva, Switzerland, pp.1064–1070, 1993.
2. 3GPP: 3rd Generation Partnership Project, "Technical Specification Group Radio Access Network, Multiplexing and Channel Coding," V8.0.0, 2007.
 粵公網(wǎng)安備 44030902003195號(hào)
粵公網(wǎng)安備 44030902003195號(hào)