示波器從誕生之處至今已經歷了第一代模擬實時示波器ART,以數字化處理和存儲功能為主要特征的第二代,以及以DPO快刷新為主要宣傳點的第三代,如今已進步到第四代數字示波器,而拉開這一時代大幕的即是力科公司2008年推出的Wave Pro 7Zi和2009年推出的Wave Master 8Zi系列示波器,無論是從帶寬、采樣率、可分析存儲、儀器響應和波形處理速度、異常問題調試、還是串行數據信號質量分析方面,都比前三代示波器有了長足的進步。
1.基礎性能指標
評價一臺示波器性能的幾個基礎指標包括帶寬、采樣率、存儲深度、觸發能力和波形處理性能。
(1)示波器的帶寬定義為前端放大器的頻響曲線下降3dB處的頻點,就是示波器的-3dB帶寬,簡稱帶寬。所以一臺6GHz帶寬的示波器測量6GHz的正弦波,幅度一定會降低3dB(約降低30%)。如果你測試的對象是PCI Express G2速率為5Gbps,那對示波器帶寬的最低要求為12.5GHz,通常的法則是最低帶寬為串行數據率的2.5倍,目的是確保采集到5次諧波分量。而對單次階躍脈沖而言,由于其沒有頻率或數據率的概念,所以必須從另外角度考量示波器帶寬,那就是上升時間。如果我們以T(scope)代表示波器的10%~90%上升時間,以T(signal)代表所測量脈沖信號的上升時間,那么兩者之間的比例即T(scope)/ T(signal)與脈沖信號測量精度將基本滿足下表所列內容。
| T(scope)/ T(signal) | 脈沖測量精度 |
| <0.1 | 優于0.5% |
| 1/3 | 5% |
| 1/2 | 12% |
| 1 | 40% |
| >1 | 不應使用 |
從表中可以看出,為了使脈沖測量精度達到5%以上,應使示波器的上升時間小于脈沖上升時間的1/3以上。例如對上升時間在100ps以內的脈沖信號進行測量,示波器的上升時間應控制在30ps以內。我們知道示波器的帶寬越高其對應的上升時間越短,對高帶寬實時數字示波器而言,兩者的乘積在0.35~0.51之間變動。30ps以內的上升時間將要求示波器帶寬達到16GHz以上。如果對上升時間50ps以內的脈沖信號測量,則要求示波器的10%~90%上升時間必須控制在17ps以內,對應示波器的帶寬將達到25GHz或者更高。力科第四代Zi系列數字示波器將帶寬提高到了30GHz,使得萬兆以太網或上升沿小于50ps的超快速脈沖在實時示波器上成為現實。
(2)AD采樣時數字示波器里非常關鍵的部分,足夠的采樣率也是保證示波器信號保真度的關鍵因素之一。
數字示波器的基本原理是模擬信號低通濾波后被等時間間隔采樣,然后數字化后由數字處理單元重構,最后以波形的形式在屏幕上顯示。采樣率越高,兩次采樣之間的時間間隔就越短,重構后的波形與真實信號的擬合程度就越高。一般情況下,應該保證在信號上升沿上至少采集4個樣點才能比較客觀的恢復出脈沖信號的真是波形并加以測量。例如,對上升時間100ps的脈沖信號,我們應該至少使用40GS/s的采樣率對信號進行采集;而對于上升時間50ps以內的脈沖信號,則至少要求示波器的實時采樣率達到80GS/s。力科第四代Zi系列數字示波器就能提供80GS/s實時采樣率,是上升時間50ps以內脈沖測量的最好選擇。力科第四代Zi系列數字示波器另一大突破是力科研制成功的單ADC芯片采樣率40GS/s,避免了采用多顆低采樣率芯片疊加采樣的示波器架構不可避免引入的沖擊電平噪聲與誤差,在最高80GS/s采樣時僅通過兩顆芯片協同工作即可完成。這樣的示波器架構大大簡化了從前端放大器到ADC采樣芯片之間的信號通路,很好的保證了高采樣時的信號一致性。值得一提的是40GS/s ADC芯片代表了全球最高的芯片設計水平,其指標記錄至今無人能破。
(3)存儲深度,也叫記錄長度,表示示波器能連續采集到的最大波形點數。過去廠商和用戶都很看重可采集存儲深度,即示波器一次采集能捕獲到最大點數。今天隨著信號的日益復雜,需要處理的任務越來越龐雜,第四代示波器引入一個全新的概念:可分析存儲深度。不僅看一次采集到的點數,還同時看復雜分析一次最多能運算的波形點數。
第三代示波器的可分析存儲深度通常都比可采集存儲深度小很多,主要是因為示波器處理速度跟不上,為防止系統崩潰而限制用戶分析波形時的存儲深度。譬如,有些示波器明明能采集到200M采樣點,但FFT運算卻限制最多到3.2M,用戶的投資得不到充分利用。
力科在第四代采用了突破性的波形處理架構Xstream II做到了業界最高的512Mpts可分析存儲深度,保證用戶購買了多少物理內存,波形采集和分析就能同時用到了多少內存,從而最大限度的保護用戶的投資。
2、Xstream II架構
隨著電子信號的日益復雜,今天的示波器已被要求能以復雜的方法處理很長內存的波形,目的是深入信號內部洞察系統和電路行為,與這種能力有關的概念是示波器的響應和速度,工程師可不愿等待很長時間才能看到結果,他們希望使用示波器的感覺是舒適和充滿信心。
與處理速度有關的因素可分為三類:
- 處理和波形讀出硬件的性能
- 操作系統
- 軟件處理數據的算法
當前的高端示波器處理平臺主要為PC,硬件性能主要由CPU、主內存和內部總線決定。
操作系統同樣很重要因為它決定了多內核、多線程模式和可尋址最大內存。力科為Wave Pro 7Zi和Wave Master 8Zi示波器配備了最強大的硬件和操作系統:CPU采用Intel Core 2 Quad(四核),每個內核的工作頻率為2.5GHz。這是一種64位處理器,擁有6Mb的二級高速緩存及工作頻率為1.33GHz的前端總線;容量最高達8Mb的DDR II主存儲器,從采集存儲器到主存儲器的傳送采用直接存儲器訪問(DMA)技術,使用4路PCIe串行通道。這些通道以高達800Mpt/s的速率把波形數據傳送傳送到主存儲器中,而不需處理器干預。由于采用了Microsoft Vista 64位操作系統,示波器軟件可以尋址到4Gb大小存儲器,而32位操作系統只可以尋址最高4Gb的存儲器。
但是對深存儲波形處理速度起決定性作用的并非硬件和操作系統,乃是軟件算法。力科公司投入巨資研發的專利技術Xstream II就是一種革命性的波形處理優化技術,正是采用該技術,才使得第四代示波器在波形處理性能方面遠勝于前三代。
Xstream 處理行為可以簡單概括為:長波形被分成許多的較小的波形片段。這些較小的波形片段以優化高速緩存利用率的方式進行處理。最后,最小的波形結果重組成最終的長波形結果。這一切聽起來非常簡單,但在實踐中實現起來非常復雜。力科在這種技術中擁有多項專利。正因如此,力科示波器的性能傳統上優于競爭對手的儀器,其處理速度要高出許多倍。力科最早在2002年Wave Master8000中引入Xstream結構,之后幾年持續進行多項結構改進,在Wave Pro 7Zi引入的Xstream II中達到頂峰。
Xstream II的關鍵構成要素包括:
- 動態放置緩沖器,改善流式結構不擅長的情況;
- 預覽模式,可以在縮放和示波器調整過程中快速初步查看波形結果;
- 中斷處理能力,可以在示波器調整過程中暫停當前處理。
動態放置緩沖器需要把緩沖器放在處理流的合適位置(見下圖),以改善處理吞吐量。

基于動態緩沖器的處理流
為了解這種影響,請記住傳統處理模式在流程的每一步都涉及緩沖器。它可以視為把緩沖器放在每一個處理單元之間。傳統示波器采用的流式模式中,在任何地方都使用落在高速緩存中的小型緩沖器,而包含全部處理結果的緩沖器則放在處理流最后。在Xstream II中,在多條處理流流經公共處理單元時將執行優化(如下圖所示),這種結構的好處是把緩沖器動態放到處理流中,避免多次進行計算。
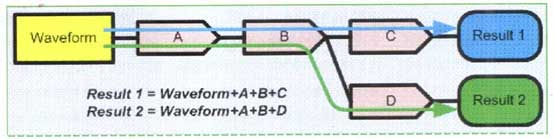
Xstream II采用的動態緩存預置與傳統簡單流式處理算法對比
Xstream II對儀器響應能力的優化主要體現在預覽處理和中斷處理能力(Preview and Abort)。這兩者結合運行的方式是,在示波器設置發生變化時,軟件開始計算新結果,同時根據屏幕畫面的重新標度來計算一個預覽結果。如果預覽在在正是處理之前完成,那么用戶先會看到預覽,然后在最終完成時看到更新的處理結果。如果正式處理先完成,那么用戶會只看到處理結果。如果在處理計算過程中,用戶修改設置,那么將中斷處理,使用新的變化重啟,用戶只看到預覽結果。在用戶設置示波器或根據測量觀察結果快速改變設置時,這種處理方法非常必要。在處理過程非常復雜耗時以及波形很長時,這種功能非常實用。如果使用其它示波器中提供的傳統處理方法,那么用戶必須待到處理結束后,才能看到顯示結果,進行另一個設置變動。在某些情況下,處理可能需要10秒以上的時間,如果用戶想改變多項設置,那么必須等每個很長處理間隔的結果之后,才能進行另一項設置變動。這種操作可能會讓用戶很不舒服,因為每步操作都需要等很長時間才能看到結果或進行下一步動作。
總之,深存儲下示波器的快速處理是適當的硬件和操作系統與適當的處理算法的結合。Xstream II是一種創新的波形處理優化技術,通過對高速緩存動態高效的處理方法,以及增加了結果預覽和處理中斷功能,實現了目前業界最杰出的儀器反應和波形處理能力。在實際應用中,Xstream II技術帶來的性能提升程度可用下列數據來印證。
- Wave Pro 7Zi做100Mpts眼圖測量時的刷新時間是20秒,而同級別的其它示波器做20Mpts眼圖需要10分鐘以上才能刷新一次,10Mpts眼圖至少需要6分鐘,100Mpts眼圖刷新速度則無法測量,因為該示波器不允許用戶對這么大的數據量做任何高級分析運算;
- Wave Pro 7Zi做FFT運算速度是3.8Mpts/秒,最多一次可分析128Mpts信號的頻譜,而DPO示波器最快的FFT運算速度是500Kpts,為了防止大數據量造成的系統崩潰或死機,這種示波器最多允許用戶運算3.2Mpts FFT;
- TriggerScan
數字示波器的一個重要應用是作為一種調試問題的工具,因此,快速查找異常事件的能力是評價示波器性能的重要標準。
電路調試通常有兩個目的:第一,找出可疑問題存在的證據;第二,找出可疑問題的更多信息使得能設定觸發隔離出異常信號。通過重復的觸發異常信號,在不同的電路測試點觀察異常事件的行為從而甄別出原因和結果之間相互關系。
定位異常信號的傳統方法是觸發信號的邊沿,用模擬余輝方式觀察疊加顯示的波形,等待一段時間后期望能從累計的波形中觀察到異常信號。采取這種方法時異常事件的捕獲率與波形的邊沿出現頻率、示波器的刷新率和異常事件發生的統計概率等相關。具體表現為如果波形的邊沿出現頻率不超過示波器的刷新率,則示波器能捕捉到每個邊沿,因此也就能捕獲到每個異常事件,反之則不能捕獲到每個邊沿。每秒捕獲到異常事件次數等于異常事件發生的概率除以邊沿頻率再除以示波器的刷新率。進一步可以指出,邊沿出現頻率小于示波器的刷新率時沒什么問題,而一旦邊沿出現頻率超過示波器的刷新率時,捕獲的概率也就對應下降。這就是為什么一些示波器廠商會創造出非常快的波形刷新模式的原因,譬如DPO。
我們可以舉例進一步說明這個問題,假設有一個200MHz的時鐘信號每5秒會出現一次毛刺,即異常出現的概率為10億分之一,利用上述公式,用一臺每秒能刷新10萬次的示波器工作在快刷新模式,需要2.8小時,這意味著每5秒出現一次的異常信號,,示波器需等待2.8小時后才能捕獲到它!效率之低,可見一斑。這里的問題是,傳統的捕獲異常信號的方法直接和刷新率成正比,但最快的刷新模式也還遠遠不夠!或者說,它們并沒有快到能解決實際問題的地步。工程師們真正需要的是一種比刷新率更快的方法。
用邊沿觸發的方法查找異常信號的問題的根本原因是每次示波器通過觸發邊沿來捕獲波形,相鄰兩次捕獲時,有一段示波器看不到的波形被稱為死區時間。很多工程師都很驚異這個死區時間相對于示波器捕獲到的時間是如此的長!在上面的例子中,示波器需要將近3小時才能看到5秒鐘出現一次的異常信號,是因為示波器只能看到邊沿出現的0.2%,在快刷新模式下也有99.8%的死區時間,在波形的每500個邊沿中,示波器只能看到一個!
我們用一種智能觸發系統來解決這個問題。當設定為觸發某個特定的智能觸發,它將查看波形的每個邊沿直到觸發成功。僅僅在智能觸發條件滿足,示波器觸發到信號的時候才有死區時間。如果設定一種智能觸發方式隔離上例中的毛刺,示波器將偵測每個邊沿直到毛刺持續,以保證異常被無一遺漏被捕獲。這種方法看上去簡單,但在設定觸發方式上有很大問題:你需要事先知道異常信號的特點,這通常是不現實的。
力科在第四代示波器中開發了一種全新的異常調試工具 TriggerScan,通過智能化使用觸發系統從而解決了上述難題。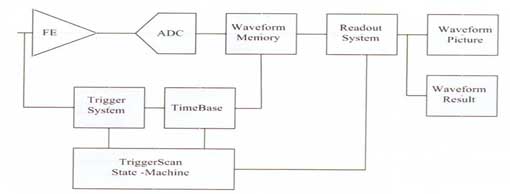
TriggerScan原理圖
TriggerScan的工作過程分為兩個階段。第一個階段操作者獲取正常的波形并訓練。在訓練過程中,示波器首先分析波形,判斷波形正常情況下的特點,然后它給出一系列的智能觸發設定,這些設定都被設計為觸發異常信號。例如,如果是時鐘信號,那么在觀察范圍內,所有的邊沿都有上升時間、周期和幅度,TriggerScan將設定出智能觸發方式來觸發超過正常范圍的斜率、周期和幅度。一旦這些智能觸發被設定,示波器進入工作的第二階段,即將這些觸發設定載入,每次按設定的某種觸發方式工作一段時間,然后繼續下次觸發動作。在任何設定下一旦捕獲到異常信號,獲得到的波形將以余輝或停住采集的方式加以顯示。
TriggerScan的有效性并非取決于邊沿的頻率。乃是與設定和使用的智能觸發的個數有關。如果設定了100中觸發方式,TriggerScan的有效性是相對于用某種特定的智能觸發方式的效率的1%。TriggerScan減小了觸發系統的有效性,但它能自動產生觸發設置并使捕獲異常信號的過程自動化。在前面的例子中,采用100000次刷新率的快刷新傳統模式,平均需要2.8小時才能找到一次異常信號。采用智能觸發系統,每5秒鐘可以看到每個異常信號。采用具有100個觸發設定的TriggerScan方法可以在平均8.3分鐘內發現一次異常信號。在這個例子中,TriggerScan方法比快刷新方法要快20倍。是否具備TriggerScan智能硬件觸發功能是第四代示波器的界定標準之一。
 粵公網安備 44030902003195號
粵公網安備 44030902003195號